Unboundedness and Downward Closures of Higher-Order Pushdown Automata
Matthew Hague |
Abstract: We show the diagonal problem for higher-order pushdown automata (HOPDA), and hence the simultaneous unboundedness problem, is decidable. From recent work by Zetzsche this means that we can construct the downward closure of the set of words accepted by a given HOPDA. This also means we can construct the downward closure of the Parikh image of a HOPDA. Both of these consequences play an important rôle in verifying concurrent higher-order programs expressed as HOPDA or safe higher-order recursion schemes.
Recent work by Zetzsche [40] has given a new technique for computing the downward closure of classes of languages. The downward closure ↓(L) of a language L is the set of all subwords of words in L (e.g. a a is a subword of b a b a b). It is well known that the downward closure is regular for any language [19]. However, there are only a few classes of languages for which it is known how to compute this closure. In general it is not possible to compute the downward closure since it would easily lead to a solution to the halting problem for Turing machines.
However, once a regular representation of the downward closure has been obtained, it can be used in all kinds of analysis, since regular languages are well behaved under all kinds of transformations. For example, consider a system that waits for messages from a complex environment. This complex environment can be abstracted by the downward closure of the messages it sends or processes it spawns. This corresponds to a lossy system where some messages may be ignored (or go missing), or some processes may simply not contribute to the remainder of the execution. In many settings – e.g. the analysis of safety properties of certain kinds of systems – unread messages or unscheduled processes do not effect the precision of the analysis. Since many types of system permit synchronisation with a regular language, this environment abstraction can often be built into the system being analysed.
Many popular languages such as JavaScript, Python, Ruby, and even C++, include higher-order features – which are increasingly important given the popularity of event-based programs and asynchronous programs based on a continuation or callback style of programming. Hence, the modelling of higher-order function calls is becoming key to analysing modern day programs.
A popular approach to verifying higher-order programs is that of recursion schemes and several tools and practical techniques have been developed [23, 38, 26, 24, 30, 5, 6, 34]. Recursion schemes have an automaton model in the form of collapsible pushdown automata (CPDA) [18] which generalises an order-2 model called 2-PDA with links [1] or, equivalently, panic automata [22]. When these recursion schemes satisfy a syntactical condition called safety, a restriction of CPDA called higher-order pushdown automata (HOPDA or n-PDA for order-n HOPDA) is sufficient [29, 21]. HOPDA can be considered an extension of pushdown automata to a “stack of stacks” structure. It remains open as to whether CPDA are strictly more expressive than nondeterministic HOPDA when generating languages of words. It is known that, at order 2, nondeterministic HOPDA and CPDA generate the same word languages [1]. However, there exists a language generated by a deterministic order-2 CPDA that cannot be generated by a deterministic HOPDA of any order [31].
It is well known that concurrency and first-order recursion very quickly leads to undecidability (e.g. [33]). Hence, much recent research has focussed on decidable abstractions and restrictions (e.g. [14, 4, 20, 27, 13, 37, 28, 10, 16]). Recently, these results have been extended to concurrent versions of CPDA and recursion schemes (e.g. [35, 25, 15, 32]). Many approaches rely on combining representations of the Parikh image of individual automata (e.g. [13, 17, 16]). However, combining Parikh images of HOPDA quickly leads to undecidability (e.g. [17]). In many cases, the downward closure of the Parikh image is an adequate abstraction.
Computing downward closures appears to be a hard problem. Recently Zetzsche introduced a new general technique for classes of automata effectively closed under rational transductions – also referred to as a full trio. For these automata the downward closure is computable iff the simultaneous unboundedness problem (SUP) is decidable.
Zetzsche used this result to obtain the downward closure of languages definable by 2-PDA, or equivalently, languages definable by indexed grammars [2]. Moreover, for classes of languages closed under rational transductions, Zetzsche shows that the simultaneous unboundedness problem is decidable iff the diagonal problem is decidable. The diagonal problem was introduced by Czerwiński and Martens [11]. Intuitively, it is a relaxation of the SUP that is insensitive to the order the characters are output. For a word w, let |w|a be the number of occurrences of a in w.
| Diagonala1, …, aα | ⎛ ⎝ | L | ⎞ ⎠ | = ∀ m . ∃ w ∈ L . ∀ 1 ≤ i ≤ α . | ⎪ ⎪ | w | ⎪ ⎪ | ai ≥ m . |
Proof. The only-if direction follows from Theorem 1 since given a language L ⊆ a1∗… aα∗ the diagonal problem is immediately equivalent to the SUP. In the if direction, the result follows since L satisfies the diagonal problem iff ↓(L) also satisfies the diagonal problem. Since the diagonal problem is decidable for regular languages and ↓(L) is regular, we have the result.
In this work, we generalise Zetzsche’s result for 2-PDA to the general case of n-PDA. We show that the diagonal problem is decidable. Since HOPDA are closed under rational transductions, we obtain decidability of the simultaneous unboundedness problem, and hence a method for constructing the downward closure of a language defined by a HOPDA.
Proof. From Theorem 3 (proved in the sequel), we know that the diagonal problem for HOPDA is decidable. Thus, using Corollary 1, we can construct the downward closure of P.
This result provides an abstraction upon which new results may be based. It also has several immediate consequences:
We present our decidability proof in two stages. First we show how to decide Diagonala(P) for a single character and HOPDA P in Sections 3 and 4. In Sections 5, 6, and 7 we generalise our techniques to the full diagonal problem.
In Section 3.1 we give an outline of the proof techniques for deciding Diagonala(P). In short, the outermost stacks of an n-PDA are created and destroyed using pushn and popn operations. These pushn and popn operations along a run of an n-PDA are “well-bracketed” (each pushn has a matching popn and these matchings don’t overlap). The essence of the idea is to take a standard tree decomposition of these well-bracketed runs and observe that each branch of such a tree can be executed by an (n−1)-PDA. We augment this (n−1)-PDA with “regular tests” that allow it to know if, each time a branch is chosen, the alternative branch could have output some a characters. If this is true, then the (n−1)-PDA outputs a single a to account for these missed characters. We prove that, although the (n−1)-PDA outputs far fewer characters, it can still output an unbounded number iff the n-PDA could. Hence, by repeating this reduction, we obtain a 1-PDA, for which the diagonal problem is decidable since it is known how to compute their downward closures [39, 9].
In Section 6.1 we outline the generalisation of the proof to the full problem Diagonala1, …, aα(P). The key difficulty is that it is no longer enough for the (n−1)-PDA to follow only a single branch of the tree decomposition: it may need up to one branch for each of the a1, …, aα. Hence, we define HOPDA that can output trees with a bounded number (α) of branches. We then show that our reduction can generalise to HOPDA outputting trees (relying essentially on the fact that the number of branches is bounded).
Given two words w = γ1 … γm∈ Σ∗ and w′ = σ1 … σl∈ Σ∗ for some alphabet Σ, we write w ≤ w′ iff there exist i1 < … < im such that for all 1 ≤ j ≤ m we have γj= σij. Given a set of words L ⊆ Σ∗, we denote its downward closure ↓(L) = {w | w ≤ w′ ∈ L}.
A Σ-labelled finite tree is a tuple T = (D, λ) where Σ is a set of node labels, and D ⊂ ℕ∗ is a finite set of nodes that is prefix-closed, that is, η δ ∈ D implies η ∈ D, and λ : D → Σ is a function labelling the nodes of the tree.
We write ε to denote the root of a tree (the empty sequence). We also write
| a | ⎡ ⎣ | T1, …, Tm | ⎤ ⎦ |
to denote the tree whose root node is labelled a and has children T1, …, Tm. That is, we define a[T1, …, Tm] = (D′, λ′) when for each δ we have Tδ= (Dδ, λδ) and D′ = {δη | η ∈ Dδ} ∪ {ε} and
| λ′ | ⎛ ⎝ | η | ⎞ ⎠ | = |
| . |
Also, let T[a] denote the tree ({ε}, λ) where λ(ε) = a. A branch in T = (D, λ) is a sequence of nodes of T, η1 ⋯ ηn, such that η1 = є, ηn = δ1 δ2 ⋯ δn−1 is maximal in D, and ηj+1 = ηj δj for each 1 ≤ j ≤ n−1.
HOPDA are a generalisation of pushdown systems to a stack-of-stacks structure. An order-n stack is a stack of order-(n−1) stacks. An order-n push operation pushes a new order-(n−1) stack onto the stack that is a copy of the existing topmost order-(n−1) stack. Rewrite operations update the character that is at the top of the topmost stacks.
|
Stacks are written with the top part of the stack to the left. We define several operations.
|
and set
| Opsn = | ⎧ ⎨ ⎩ | rewγ | ⎪ ⎪ | γ ∈ Γ | ⎫ ⎬ ⎭ | ⋃ | ⎧ ⎨ ⎩ | pushk, popk | ⎪ ⎪ | 1 ≤ k ≤ n | ⎫ ⎬ ⎭ |
to be the set of order-n stack operations.
For example
|
We write (p, γ) —a→ (p′, o) for a rule (p, γ, a, o, p′) ∈ R.
A configuration of an n-PDA is a tuple ⟨ p, s ⟩ where p ∈ P and s is an order-n stack over Γ. We have a transition ⟨ p, s ⟩ —a→ ⟨ p′, s′ ⟩ whenever we have (p, γ) —a→ (p′, o), top1(s) = γ, and s′ = o(s).
A run over a word w ∈ Σ∗ is a sequence of configurations c0 —a1→ ⋯ —am→ cm such that the word a1…am is w. It is an accepting run if c0 = ⟨ pin, [[ γin ]] ⟩ — where we write [[ γ ]] for [⋯[γ]1⋯]n — and where cm= ⟨ p, s ⟩ with p ∈ F. Furthermore, for a set of configurations C, we define
| PreP∗ | ⎛ ⎝ | C | ⎞ ⎠ |
to be the set of configurations c such that there is a run over some word from c to c′ ∈ C. When C is defined as the language of some automaton A accepting configurations, we abuse notation and write PreP∗(A) instead of PreP∗(L(A)).
For convenience, we sometimes allow a set of characters to be output instead of only one. This is to be interpreted as outputing each of the characters in the set once (in some arbitrary order). We also allow sequences of operations o1; …; om in the rules instead of single operations. When using sequences we allow a test operation γ? that only allows the sequence to proceed if the top1 character of the stack is γ. All of these extensions can be encoded by introducing intermediate control states.
We will need to represent sets of stacks. To do this we will use automata to recognise stacks. We define the stack automaton model of Broadbent et al. [8] restricted to HOPDA rather than CPDA. We will sometimes call these bottom-up stack automata or simply automata. The automata operate over stacks interpreted as words, hence the opening and closing braces of the stacks appear as part of the input. We annotate these braces with the order of the stack the braces belong to. Let Γ[] = {[n−1,…,[1, ]1,…,]n−1} ⊎ Γ. Note, we don’t include [n, ]n since these appear exclusively at the start and end of the stack.
Representing higher order stacks as a linear word graph, where the start of an order-k stack is an edge labelled [k and the end of an order-k stack is an edge labelled ]k, a run of a bottom-up stack automaton is a labelling of the nodes of the graph with states in Q such that
The run is accepting if the leftmost (initial) node is labelled by q ∈ QF. An example run over the word graph representation of [ [ [γ σ]1[σ]1 ]2 [ [σ]1 ]2 ]3 is given in Figure 1.
Let L(A) be the set of stacks with accepting runs of A. Sometimes, for convenience, if we have a configuration c = ⟨ p, s ⟩ of a HOPDA, we will write c ∈ L(A) when s ∈ L(A).
We assume Σ = {a, ε} and use b to range over Σ. This can be obtained by simply replacing all other characters with ε. We also assume that all rules of the form (p, γ) —b→ (p′, o) with o = pushn or o = popn have b = ε. We can enforce this using intermediate control states to first apply o in one step, and then in another output b (the stack operation on the second step will be rewγ where γ is the current top character). We start with an outline of the proof, and then explain each step in detail.
For convenience, we assume acceptance is by reaching a unique control state in F with an empty stack (i.e. the lowermost stack was removed with a popn and F = {pf}). This can easily be obtained by adding a rule to a new accepting state whenever we have a rule leading to a control state in F. From this new state we can loop and perform popn operations until the stack is empty.
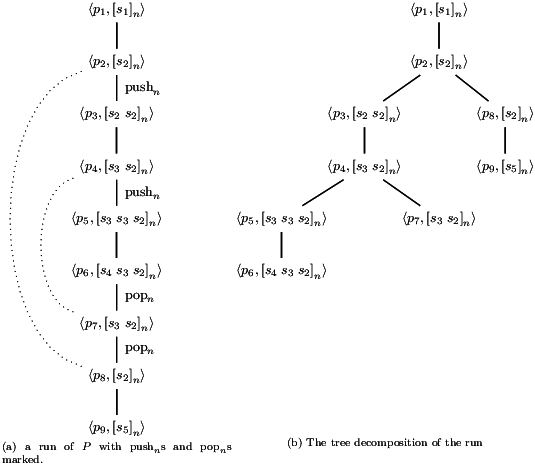
The approach is to take an n-PDA P and produce an (n−1)-PDA P−1 that satisfies the diagonal problem iff P does. The idea behind this reduction is that an (accepting) run of P can be decomposed into a tree with out-degree at most 2: each pushn has a matching popn that brings the stack back to be the same as it was before the pushn; we cut the run at the popn and hang the tail next to the pushn and repeat this to form a tree from a run. This is illustrated in Figure 2 where nodes are labelled by their configurations, and the pushn and popn points are marked. The dotted arcs connect nodes matched by their pushes and pops – these nodes have the same stacks. Notice that at each branching point, the left and right subtrees start with the same order-(n−1) stacks on top. Notice also that for each branch, none of its transitions remove the topmost order-(n−1) stack. Hence, we can produce an (n−1)-PDA that picks a branch of this tree decomposition to execute and only needs to keep track of the topmost order-(n−1) stack of the n-PDA. When picking a branch to execute, the (n−1)-PDA outputs a single a if the branch not chosen could have output some a characters. We prove that this is enough to maintain unboundedness.
In more detail, we perform the following steps.
| Diagonala | ⎛ ⎝ | P | ⎞ ⎠ | ⇐⇒ Diagonala | ⎛ ⎝ | P′ | ⎞ ⎠ | . |
The (n−1)-PDA with tests P−1 will simulate the n-PDA P in the following way.
Although P−1 will output far fewer a characters than P (since it does not execute the full run), we show that it still outputs enough as for the language to remain unbounded.
We thus have the following theorem.
Proof. We construct via Lemma 2 an (n−1)-PDA P′ such that Diagonala(P) iff Diagonala(P′). We repeat this step until we have a 1-PDA. It is known that Diagonala(P) for an 1-PDA is decidable since it is possible to compute the downward closure [39, 9].
When executing a branch of the tree decomposition, to be able to ensure the branch is correct and whether we should output an extra a we need to know how the system could have behaved on the skipped branch. To do this we add tests to the HOPDA that allow it to know if the current stack belongs to a given regular set. We show in the following sections that the properties required for our reduction can be represented as regular sets of stacks. Although we take Broadbent et al.’s logical reflection as the basis of our proof, HOPDA with tests can be seen as a generalisation of pushdown systems with regular valuations due to Esparza et al. [12].
| R ⊆ P × Γ × | ⎧ ⎨ ⎩ | A1, …, Am | ⎫ ⎬ ⎭ | × Σ × Opsn × P |
We write (p, γ, Ai) —b→ (p′, o) for (p, γ, Ai, b, o, p′) ∈ R. We have a transition ⟨ p, s ⟩ —b→ ⟨ p′, s′ ⟩ whenever (p, γ, Ai) —b→ (p′, o) ∈ R and top1(s) = γ, s ∈ L(Ai), and s′ = o(s).
We know from Broadbent et al. that these tests do not add any extra power to HOPDA. Intuitively, we can embed runs of the automata into the stack during runs of the HOPDA.
Proof. This is a straightforward adaptation of Broadbent et al. [8]. A more general theorem is proved in Theorem 1.
When the HOPDA is in a configuration of the form ⟨ p, [s]n ⟩ – i.e. the outermost stack contains only a single order-(n−1) stack – we require the HOPDA to be able to know whether,
Given P, we first augment P to record whether an a has been produced. This can be done simply by recording in the control state whether a has been output.
| Pa = | ⎛ ⎝ | P ⋃ Pa, Σ, Γ, R ⋃ Ra, F ⋃ Fa, pin, γin | ⎞ ⎠ |
|
It is easy to see that P and Pa accept the same languages, and that Pa is only in a control state pa if an a has been output.
Fix some P = (P, Σ, Γ, R, F) and Pa = (Pa, Σ, Γ, Ra, Fa). To obtain a HOPDA with tests, we need, for each p1, p2 ∈ P the following automata. Note, we define these automata to accept order-(n−1) stacks since they will be used in an (n−1)-PDA with tests.
To do this we will use a reachability result due to Broadbent et al. that appeared in ICALP 2012 [7]. This result uses an automata representation of sets of configurations. However, these automata are slightly different in that they read full configurations “top down”, whereas the automata of Theorem 2 (Removing Tests) read only stacks “bottom up”.
It is known that these two representations are effectively equivalent, and that both form an effective boolean algebra [8, 7]. In particular, for a top-down automaton A and a control state p we can build a bottom-up stack automaton B such that ⟨ p, s ⟩ ∈ L(A) iff s ∈ L(B) and vice versa. We recall the reachability result.
Let Ap, γ be a top-down automaton accepting configurations of the form ⟨ p, [s]n ⟩ where top1(s) = γ. Next, let
| Ap = |
| Ap′, γ |
and
| Apa= |
| Ap′a, γ |
I.e. Ap and Apa accept configurations of Pa from which it is possible to perform a popn operation to p and reach the empty stack.
It is easy to see both Ap1, p2 and Ap1, p2a are regular and representable by bottom-up automata since both
| PreP∗ | ⎛ ⎝ | Ap2 | ⎞ ⎠ | and PrePa∗ | ⎛ ⎝ | Ap2a | ⎞ ⎠ |
are regular from Theorem 3, and bottom-up and top-down automata are effectively equivalent. To enforce only stacks of the form [s]n we intersect with an automaton A1 accepting all stacks containing a single order-(n−1) stack (this is clearly regular).
We are now ready to complete the reduction. Correctness is shown in Section 4. Let Att be the automaton accepting all stacks. In the following definition, a control state (p1, p2) means that we are currently in control state p1 and are aiming to empty the stack on reaching p2, and the rules Rsim simulate all operations apart from pushn and popn directly, Rfin detect when the run is accepting, Rpush follow the push branch of the tree decomposition, using tests to ensure the existence of the pop branch, and Rpop follow the pop branch of the tree decomposition, also using tests to check the existence of the push branch.
| P−1 = | ⎛ ⎝ |
| ⎞ ⎠ |
|
| ⎛ ⎝ |
| ⎞ ⎠ | —b→ | ⎛ ⎝ |
| ⎞ ⎠ |
| ⎛ ⎝ |
| ⎞ ⎠ | —ε→ | ⎛ ⎝ | f, rewγ | ⎞ ⎠ |
| ⎛ ⎝ |
| ⎞ ⎠ | —ε→ | ⎛ ⎝ |
| ⎞ ⎠ |
| ⎛ ⎝ |
| ⎞ ⎠ | —a→ | ⎛ ⎝ |
| ⎞ ⎠ |
| ⎛ ⎝ |
| ⎞ ⎠ | —ε→ | ⎛ ⎝ |
| ⎞ ⎠ |
| ⎛ ⎝ |
| ⎞ ⎠ | —a→ | ⎛ ⎝ |
| ⎞ ⎠ |
In the next section, we show the reduction is correct.
To complete the reduction, we convert the HOPDA with tests into a HOPDA without tests.
| Diagonala | ⎛ ⎝ | P | ⎞ ⎠ | ⇐⇒ Diagonala | ⎛ ⎝ | P′ | ⎞ ⎠ | . |
Proof. From Definition 4 (P−1) and Lemma 1 (Correctness of P−1), we obtain from P an (n−1)-PDA with tests P−1 satisfying the conditions of the lemma. To complete the proof, we invoke Theorem 2 (Removing Tests) to find P′ as required.
This section is dedicated to the proof of Lemma 1 (Correctness of P−1).
The idea of the proof is that each run of P can be decomposed into a tree: each pushn operation creates a node whose left child is the run up to the matching popn, and whose right child is the run after the matching popn. All other operations create a node with a single child which is the successor configuration.
Each branch of such a tree corresponds to a run of P−1. To prove that P−1 can output an unbounded number of as we prove that any tree containing m edges outputting a must have a branch along which P−1 would output log(m) a characters. Thus, if P can output an unbounded number of a characters, so can P−1.
Given a run
| ρ = c0 —b1→ c1 —b2→ ⋯ —bm→ cm |
of P where each pushn operation has a matching popn, we can construct a tree representation of ρ inductively. That is, we define Tree(c) = T[ε] for the single-configuration run c, and, when
| ρ = c —b→ ρ′ |
where the first rule applied does not contain a pushn operation, we have
| Tree | ⎛ ⎝ | ρ | ⎞ ⎠ | = b | ⎡ ⎣ |
| ⎤ ⎦ |
and, when
| ρ = c0 —ε→ ρ1 —ε→ ρ2 |
with c1 being the first configuration of ρ2 and where the first rule applied in ρ contains a pushn operation, c0 = ⟨ p, s ⟩ and c1 = ⟨ p′, s ⟩ for some p, p′, s and there is no configuration in ρ1 of the form ⟨ p″, s ⟩, then
| Tree | ⎛ ⎝ | ρ | ⎞ ⎠ | = ε | ⎡ ⎣ |
| ⎤ ⎦ | . |
An accepting run of P has the form ρ —ε→ c where ρ has the property that all pushn operations have a matching popn and the final transition is a popn operation to c = ⟨ p, []n ⟩ for some p ∈ F. Hence, we define the tree decomposition of an accepting run to be
| Tree | ⎛ ⎝ | ρ —ε→ c | ⎞ ⎠ | = ε | ⎡ ⎣ |
| ⎤ ⎦ | . |
In the above tree decomposition of runs, the tree branches at each instance of a pushn operation. This mimics the behaviour of P−1, which performs such branching non-deterministically. Hence, given a run ρ of P, each branch of Tree(ρ) corresponds to a run of P−1.
We formalise this intuition in the following section. In this section, we assign scores to each subtree T of Tree(ρ). These scores correspond directly to the largest number of a characters that P−1 can output while simulating a branch of T.
Note, in the following definition, we exploit the fact that only nodes with exactly one child may have a label other than ε. We also give a general definition applicable to trees with out-degree larger than 2. This is needed in the simultaneous unboundedness section. For the moment, we only have trees with out-degree at most 2.
Let
| = |
| and |
| = |
| . |
Then,
| Score | ⎛ ⎝ | T | ⎞ ⎠ | = |
|
We then have the following lemma for trees with out-degree 2.
| Score | ⎛ ⎝ | T | ⎞ ⎠ | ≥ log | ⎛ ⎝ | m | ⎞ ⎠ |
Proof. The proof is by induction over m. In the base case m = 1 and there is a single node η in T labelled a. By definition, the subtree T′ rooted at η has Score(T′) = 1. Since the score of a tree is bounded from below by the score of any of its subtrees, we have Score(T) ≥ log(1) as required.
Now, assume m > 1. Find the smallest subtree T′ of T containing m nodes labelled a. We necessarily have either
In case (1) we have by induction
| Score | ⎛ ⎝ | T′ | ⎞ ⎠ | = 1 + log | ⎛ ⎝ | m − 1 | ⎞ ⎠ | ≥ log | ⎛ ⎝ | m | ⎞ ⎠ |
In case (2) we have
| Score | ⎛ ⎝ | T′ | ⎞ ⎠ | = max | ⎛ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎠ | . |
We pick whichever of T1 and T2 has the most nodes labelled a. This tree has at least ⌈m / 2⌉ nodes labelled a. Note, since both trees contain nodes labelled a, the right-hand side of the addition is always 1. Hence, we need to show
| log | ⎛ ⎝ |
| ⎞ ⎠ | + 1 ≥ log | ⎛ ⎝ | m | ⎞ ⎠ |
which follows from
|
By our choice of T′ we thus have Score(T) = Score(T′) ≥ log(m) as required.
Proof. Let pf be the final (accepting) control state of P and let T = Tree(ρ). We begin at the root node of T, which corresponds to the initial configuration of ρ. Let ⟨ p, [s]n ⟩ be this initial configuration and let ⟨ (p, pf), s ⟩ be the initial configuration of P−1.
Thus, assume we have a node η of T, with a corresponding configuration c = ⟨ p, s ⟩ of P and configuration c−1 = ⟨ (p, ppop), topn(s) ⟩ of P−1 and a run ρ−1 of P−1 ending in c−1 and outputting (m − Score(T′)) a characters where T′ is the subtree of T rooted at η. The subtree T′ corresponds to a sub-run ρ′ of ρ where the transition immediately following ρ′ is a popn transition to a control state ppop.
There are two cases when we are dealing with internal nodes.
In this case there is a transition c —b→ c′ via a rule (p, γ) —b→ (p′, o) where o ∉ {pushn, popn}. Hence, we have the rule ((p, ppop), γ, Att) —b→ ((p′, ppop), o) in P−1 and thus we can extend ρ−1 with a transition c−1 —b→ c′−1 via this rule where ρ−1, c′ and c′−1 maintain the assumptions above.
In this case we have that T′ corresponds to a sub-run
| c —ε→ ρ1 —ε→ ρ2 |
of ρ. The transition from c to the beginning of ρ1 is via a rule r1 = (p, γ) —ε→ (p1, pushn) and the transition from the end of ρ1 to the start of ρ2 is via a rule r2 = (p2, γ1) —ε→ (p3, popn). Moreover, from the definition of the decomposition, the final configuration in ρ2 is followed in ρ by a pop rule r3 = (p4, γ2) —ε→ (ppop, popn).
There are two further cases depending on whether the score of T′ is derived from the score of T1 or T2.
If an a is output, we have c−1 ∈ L(Ap3, ppopa) and Score(T′) − Score(T1) = 1. We can extend ρ via an application of the rule ((p, ppop), γ, Ap3, ppopa) —a→ ((p1, p3), rewγ) that exists in P−1 since c−1 ∈ L(Ap3, ppopa). This transition maintains the property on the stacks since the pushn copies the topmost stack, hence P−1 does not need to change its stack. It maintains the property on the scores since it outputs a, accounting for the part of the score contributed by T2. Finally, the condition on control states is satisfied since the second component is set to p2.
If an a is not output, then the case is similar to the above, except T2 does not contribute to the score, we have c−1 ∈ L(Ap3, ppop), and the transition of P−1 is labelled ε instead of a.
If an a is output, we have c−1 ∈ L(Ap1, p3a) and Score(T′) − Score(T2) = 1. We can extend ρ via an application of the rule ((p, ppop), γ, Ap1, p3a) —a→ ((p3, ppop), rewγ) that exists in P−1 since c−1 ∈ L(Ap1, p3a) This transition maintains the property on the stacks since the stack after the popn is identical to the stack before the pushn, hence P−1 does not need to change its stack. It maintains the property on the scores since it outputs a, accounting for the part of the score contributed by T1. Finally, the condition on control states is satisfied since the second component is unchanged.
If an a is not output, then the case is similar to the above, except T1 does not contribute to the score, we have c−1 ∈ L(Ap1, p3) and the transition of P−1 is labelled ε instead of a.
Finally, we reach a leaf node η with a run outputting the required number of as. We need to show that the run constructed is accepting. Let η′ be the first ancestor of η that contains η in its leftmost subtree. Let T′ be the subtree rooted at η′. This tree corresponds to a sub-run ρ′ of ρ that is followed immediately by a popn rule (p, γ) —ε→ (ppop, popn). Moreover, we have ((p, ppop), γ, Att) —ε→ (f, rewγ) with which we can complete the run of P−1 as required.
Finally, we need to show that each accepting run of P−1 gives rise to an accepting run of P containing at least as many as.
Proof. Let pf be the unique accepting conrol state of P. Take an accepting run ρ−1 of P−1. We show that there exists a corresponding run ρ of P outputting at least as many as.
Let
| c0 —b→ ⋯ —b→ cm—ε→ ⟨ f, s ⟩ |
for some s be the accepting run of P−1. We define inductively for each 0 ≤ i ≤ m a pair of runs ρ1i, ρ2i of P such that
Initially we have c0 = ⟨ (pin, pf), s ⟩ and s = [[ γin ]]. We define ρ10 = ⟨ pin, [s]n ⟩ and ρ20 = ⟨ pf, []n ⟩ which immediately satisfy the required conditions.
Assume we have ρ1i and ρ2i as required. We show how to obtain ρ1i+1 and ρ2i+1. There are several cases depending on the rule used on the transition ci—bi+1→ ci+1. Let ci= ⟨ (p, ppop), s ⟩, the final configuration of ρ1i be ⟨ p, [s s1 … sl]n ⟩ and the first configuration of ρ2i be ⟨ ppop, [s1 … sl]n ⟩.
The required conditions are inherited from ρ1i and ρ2i since o only changes the topn stack, the final configuration of ρ2i+1 is the same as ρ2i, ppop is not changed, and the rule of P outputs an a iff the rule of P−1 does.
Since the final configuration of ρ1i+1 is ⟨ p′, [s s s1 … sl]n ⟩ it is easy to check the required correspondence with the first configuration ⟨ p′pop, [s s1 … sl]n ⟩ of ρ2i+1.
The remaining conditions are immediate since no a is output and the final configuration of ρ2i+1 is the same as ρ2i.
To verify that the properties hold, we observe that ci+1 = ⟨ (p2, ppop), s ⟩, and ρ1i+1 ends with ⟨ p2, [s s1 … sl]n ⟩ and ρ2i+1 still begins with ⟨ ppop, [s1 … sl]n ⟩ and has the required final configuration. The property on the number of as holds since the rule of P−1 did not output an a.
Finally, when we reach i = m we have from the final transition of the run of P−1 that there is a rule (p, γ) —ε→ (ppop, popn). We combine ρ1m and ρ2m with this pop transition, resulting in an accepting run of P that outputs at least as many a characters as the run of P−1.
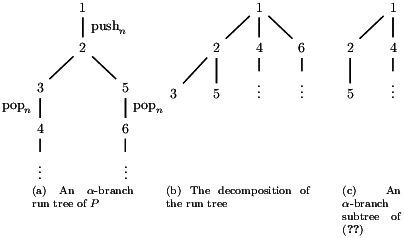
We generalise the previous result to the full diagonal problem. Naïvely, the previous approach cannot work. Consider the HOPDA executing
| push1m; pushn; pop1m; popn; pop1m |
where the first sequence of pop1 operations output a1 and the second sequence output a2.
The corresponding run trees are of the form given in Figure 3. In particular, P−1 can only choose one branch, hence all runs of P−1 produce a bounded number of a1s or a bounded number of a2s. They cannot be simultaneously unbounded.
For P−1 to be able to output both an unbounded number of a1 and a2 characters, it must be able to output two branches of the tree. To this end, we define a notion of α-branch HOPDA, which output trees with up to α branches. We then show that the reduction from n-PDA to (n−1)-PDA can be generalised to α-branch HOPDA.
We define n-PDA outputting trees with at most α branches, denoted (n, α)-PDA. Note, an n-PDA that outputs a word is an (n, 1)-PDA. Indeed, any (n, α)-PDA is also an (n, α′)-PDA whenever α ≤ α′.
We use the notation (p, γ) —b→ (p1, …, pm, o) to denote a rule (p, γ, b, o, p1, …, pm) ∈ R. Intuitively, such a rule generates a node of a tree with m children. The purpose of the mapping θ is to bound the number of branches that this tree may have. Hence, at each branching rule, the quota of branches is split between the different subtrees. The existence of such a mapping implies this information is implicit in the control states and an (n, α)-PDA can only output trees with at most α branches.
From the initial configuration c0 = ⟨ pin, [[ γin ]] ⟩ a run of an (n, α)-PDA is a tree T = (D, λ) whose nodes are labelled with n-PDA configurations, and generates an output tree T′ = (D, λ′) whose nodes are labelled with symbols from the output alphabet. Precisely
The run is accepting if for all leaf nodes η we have λ(η) = ⟨ p, []n ⟩ and p ∈ F. Let L(P) be the set of output trees of P.
Given an output tree T we write |T|a to denote the number of nodes labelled a in T. For an (n, α)-PDA P, we define
| Diagonala1, …, aα | ⎛ ⎝ | P | ⎞ ⎠ | = |
| ∀ m . ∃ T ∈ L | ⎛ ⎝ | P | ⎞ ⎠ | . ∀ 1 ≤ i ≤ α . | ⎪ ⎪ | T | ⎪ ⎪ | ai ≥ m . |
Given an (n, α)-PDA P we construct an (n−1, α)-PDA P−1 such that
| Diagonala1, …, aα | ⎛ ⎝ | P | ⎞ ⎠ | ⇐⇒ Diagonala1, …, aα | ⎛ ⎝ | P−1 | ⎞ ⎠ | . |
Moreover, we show Diagonala1, …, aα(P) is decidable for a (0, α)-PDA (i.e. a regular automaton outputting an α-branch tree) P.
For simplicity, we assume for all rules (p, γ) —b→ (p1, …, pm, o) if m > 1 then o = rewγ (i.e. the stack is unchanged). Additionally we have b = ε.
We also make analogous assumptions to the single character case. That is, we assume Σ = {a1, …, aα, ε} and use b to range over Σ. Moreover, all rules of the form (p, γ) —b→ (p′, o) with o = pushn or o = popn have b = ε. Finally, we assume acceptance is by reaching a unique control state in F with an empty stack.
We briefly sketch the intuition behind the algorithm. We illustrate the reduction from (n, α)-PDA to (n−1, α)-PDA in Figure 4.
As before, we instrument our HOPDA with tests. Removing these tests requires a simple adaptation of Broadbent et al. [8].
We use the notation (p, γ, A) —b→ (p1, …, pm, o) to denote a rule (p, γ, A, b, o, p1, …, pm) ∈ R.
From the initial configuration c0 = ⟨ pin, [[ γin ]] ⟩ a run of an (n, α)-PDA with tests is a tree T = (D, λ) and generates an output tree ρ = (D, λ′) where
The run is accepting if for all leaf nodes η we have λ(η) = ⟨ p, []n ⟩ and p ∈ F. Let L(P) be the set of output trees of P.
Proof. This is a straightforward adaptation of Broadbent et al. [8]. Let the (n, α)-PDA with tests be P = (P, Σ, Γ, R, F, pin, γin, θ) with test automata A1, …, Am. We build an (n, α)-PDA that mimics P almost directly. The only difference is that each character γ appearing in the stack is replaced by
| ⎛ ⎜ ⎝ |
| ⎞ ⎟ ⎠ | . |
For each test A we have a vector of functions
| = | ⎛ ⎝ | τ1, …, τn | ⎞ ⎠ | . |
The function τk : Q → Q intuitively describes runs of A from the bottom of topk+1(s) to the top of popk(topk+1(s)). Thus, we can reconstruct an entire run over pop1(s) from initial state q as
| q′ = τ1 | ⎛ ⎝ |
| ⎞ ⎠ |
and then we can consult Δ to complete the run by adding the effect of reading top1(s).
Thus, let Ai= (Qi, Γ[], qini, Δi, QFi). We define
| PT = | ⎛ ⎝ | P, Σ, ΓT, RT, F, pin, γinT, θ | ⎞ ⎠ |
where
| ΓT = | ⎧ ⎨ ⎩ |
| ⎪ ⎪ ⎪ |
| ⎫ ⎬ ⎭ |
and RT is the smallest set of rules of the form
| ⎛ ⎝ | p, γT | ⎞ ⎠ | —b→ | ⎛ ⎝ |
| ⎞ ⎠ |
where γT = (γ, τ1, …, τm) and (p, γ, Ai) —b→ (p1, …, pl, o) ∈ R and Accepts(γ, τi, Δi, qini, QFi) and we define
|
where Δ(q, [n ⋯ [1 γ) is shorthand for the repeated application of Δ on γ then [1, back to [n, and we define Update(o, γT) = oT following the cases below. Let γT = (γ, τ1, …, τm).
| i = | ⎛ ⎝ | τ1, …, τk−1, τk′, τk+1, … τn | ⎞ ⎠ |
| τk′ | ⎛ ⎝ | q | ⎞ ⎠ | = τk | ⎛ ⎝ |
| ⎞ ⎠ | . |
| oT = popo; |
| ?; rew |
|
| i″ = | ⎛ ⎝ | τ1′, …, τk−1′, τk, … τn | ⎞ ⎠ | . |
Finally, we set γinT = (γin, τ1, …, τm) where for each i we have τi = (τ1, …, τn) such that for each k we have τk(q) = Δ(q, ]k ⋯ ]n).
Previously we built automata Ap1, p2 to indicate that from p1, the current top stack could be removed, arriving at p2. This is fine for words, however, we now have α-branch trees. It is no longer enough to specify a single control state: the top stack may be popped once on each branch of the tree, hence for a control state p we need to recognise configurations with control state p from which there is a run tree where the leaves of the trees are labelled with configurations with control states p1, …, pm and empty stacks. Moreover we need to recognise the set O of characters output by the run tree. More precisely, for these automata we write
| Ap,p1,…,pmO |
where θ(p) ≥ θ(p1) + ⋯ + θ(pm) and O ⊆ {a1, …, aα}. We have s ∈ L(Ap,p1,…,pmO) iff there is a run tree T with the root labelled ⟨ p, [s]n ⟩ and m leaf nodes labelled ⟨ p1, []n ⟩, …, ⟨ pm, []n ⟩ respectively. Moreover, we have a ∈ O iff the corresponding output tree T′ has |T′|a > 0.
To construct the required stack automata, we need to do reachability analysis of (n, α)-PDA. We show that such analyses can be rephrased in terms of alternating higher-order pushdown systems (HOPDS), for which the required algorithms are already known [7]. Note, we refer to these machines as “systems” rather than “automata” because they do not output a language.
| R ⊆ | ⎛ ⎝ | P × Γ × Opsn × P | ⎞ ⎠ | ⋃ | ⎛ ⎝ | P × Γ × 2P | ⎞ ⎠ |
We write (p, γ) → (p, o) to denote (p, γ, o, p) ∈ R and (p, γ) → p1, …, pm to denote (p, γ, {p1, …, pm}) ∈ R.
An run of an alternating HOPDS may split into several configurations, each of which must reach a target state. Hence, the branching of the alternating HOPDS mimics the branching of the (n, α)-PDA. Given a set C of configurations, we define PreP∗(C) to be the smallest set C′ such that
|
In order to use standard results to obtain Ap,p1,…,pmO we construct an alternating HOPDS P⋄ and automaton A such that checking c ∈ PreP⋄∗(A) for a suitably constructed c allows us to check whether s ∈ L(Ap,p1,…,pmO).
The alternating HOPDS P⋄ will mimic the branching of P with alternating transitions1 (p, γ) → p1, …, pm of P⋄. It will maintain in its control states information about which characters have been output, as well as which control states should appear on the leaves of the branches. This final piece of information prevents all copies of the alternating HOPDS from verifying the same branch of P.
| P⋄ = | ⎛ ⎝ | P⋄, Γ, R⋄ | ⎞ ⎠ |
| P⋄ = | ⎧ ⎪ ⎪ ⎨ ⎪ ⎪ ⎩ |
| ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ |
| ⎫ ⎪ ⎪ ⎬ ⎪ ⎪ ⎭ |
| ⎛ ⎝ | p, γ | ⎞ ⎠ | —b→ | ⎛ ⎝ | p′, o | ⎞ ⎠ | ∈ R |
| ⎛ ⎝ |
| ⎞ ⎠ | → | ⎛ ⎜ ⎝ |
| ⎞ ⎟ ⎠ |
| ⎛ ⎝ | p, γ | ⎞ ⎠ | —ε→ | ⎛ ⎝ | p1, …, pm, rewγ | ⎞ ⎠ | ∈ R |
| ⎛ ⎝ |
| ⎞ ⎠ | → |
|
In the above definition, the permutation condition ensures that the target control states are properly distributed amongst the newly created branches.
| ⟨ |
| , |
| ⟩ ∈ PreP⋄∗ | ⎛ ⎝ | A | ⎞ ⎠ |
| L | ⎛ ⎝ | A | ⎞ ⎠ | = | ⎧ ⎨ ⎩ |
| ⎪ ⎪ ⎪ |
| ⎫ ⎬ ⎭ | . |
Proof. First take s ∈ L(Ap,p1,…,pmO) and the run tree witnessing this membership. We can move down the tree, maintaining a frontier c1, …, cl and building a tree witnessing that ⟨ (p, O, p1, …, pm), [s]n ⟩ ∈ PreP⋄∗(A). Initially we have the frontier ⟨ p, [s]n ⟩ and the initial configuration ⟨ (p, O, p1, …, pm), [s]n ⟩.
Hence, take a configuration c = ⟨ p′, s′ ⟩ from the frontier and corresponding configuration c′ = ⟨ (p′, O′, p′1, …, p′i), s′ ⟩. If the rule applied to c is not a branching rule, we simply take the matching rule of P⋄ and apply it to c′. Note, that if the rule output b we remove b from O′. Hence, O′ contains only characters that have not been output on the path from the initial configuration.
If the rule applied is branching, that is (p′, γ) —ε→ (p″1, …, p″j, rewγ) then we apply the rule
| ⎛ ⎝ |
| ⎞ ⎠ | → |
|
where p′1, …, p′i is a permutation of p11, …, pi11, … p1j, …, pijm and O = O1 ∪ ⋯ ∪ Om. These partitions are made in accordance with the distribution of the leaves and outputs of the run tree of P. I.e. if a control state p″ appears on the i′th subtree, then it should appear in the i′th target state of P⋄. Similarly, if the i′th subtree outputs an b ∈ O, then b should be placed in Oi′. Applying this alternating transition creates a matching configuration for each new branch in the frontier.
We continue in this way until we reach the leaf nodes of the frontier. Each leaf ⟨ p′, s ⟩ has a matching ⟨ (p′, ∅, p′), s ⟩ and hence is in L(A). Thus, we have witnessed ⟨ (p, O, p1, …, pm), [s]n ⟩ ∈ PreP⋄∗(A) as required.
To prove the other direction, we mirror the previous argument, showing that the witnessing tree for P⋄ can be used to build a run tree of P.
It is known that PreP∗(A) is computable for alternating HOPDS.
Hence, we can now build Ap,p1,…,pmO from the control state p and top-down automaton representation of PreP⋄∗(A) since we can effectively translate from top-down to bottom-up stack automata.
We generalise our reduction to (n, α)-PDA. Let Att be the automata accepting all configurations. Note, in the following definition we allow all transitions (including branching) to be labelled by sets of output characters. To maintain our assumed normal form we have to replace these transitions using intermediate control states to ensure all branching transitions are labelled by ε and all transitions labelled O are replaced by a sequence of transitions outputting a single instance of each character in O.
The construction follows the intuition of the single character case, but with a lot more bookkeeping. Given an (n, α)-PDA P we define an (n−1, α)-PDA with tests P−1 such that P satisfies the diagonal problem iff P−1 also satisfies the diagonal problem. The main control states of P−1 take the form
| ⎛ ⎝ | p, p1, …, pm, O, B | ⎞ ⎠ |
where p, p1, …, pm are control states of P and both O and B are sets of output characters. We explain the purpose of each of these components.
We will define P−1 to generate up to m branches of the tree decomposition of a run of P. In particular, for each of the characters a ∈ {a1, …, aα} there will be a branch of the run of P−1 responsible for outputting “enough” of the character a to satisfy the diagonal problem. Note that two characters a and a′ may share the same branch. When a control state of the above form appears on a node of the run tree, the final component B makes explicit which characters the subtree rooted at that node is responsible for generating in large numbers. Thus, the initial control state will have B = {a1, …, aα} since all characters must be generated from this node. However, when the output tree branches – i.e. a node has more than one child – the contents of B will be partitioned amongst the children. That is, the responsibility of the parent to output enough of the characters in B is divided amongst its children.
The remaining components play the role of a test Ap,p1,…,pmO. That is, the current node is simulating the control state p of P, and is required to produce m branches, where the stack is emptied on each leaf and the control states appearing on these leaves are p1, …, pm. Moreover, the tree should output at least one of each character in O.
Note, P−1 also has (external) tests of the form Ap,p1,…,pmO that it can use to make decisions, just like in the single character case. However, it also performs tests “online” in its control states. This is necessary because the tests were used to check what could have happened on branches not followed by P−1. In the single character case, there was only one branch, hence P−1 would uses tests to check all the branches not followed, and then continue down a single branch of the tree. In the multi-character case the situation is different. Suppose a subtree rooted at a given node was responsible for outputting enough of both a1 and a2. Amongst the possible children of this node we may select two children: one for outputting enough a1 characters, and one for outputting enough a2 characters. The alternatives not taken will be checked using tests as before. However, the child responsible for outputting a1 may have also wanted to run a test on the child responsible for outputting a2. Thus, as well as having to output enough a2 characters, this latter child will also have to run the test required by the former. Thus, we have to build these tests into the control state. As a sanity condition we enforce O ∩ B = ∅ since a branch outputting a should never ask itself if it is able to produce at least one a.
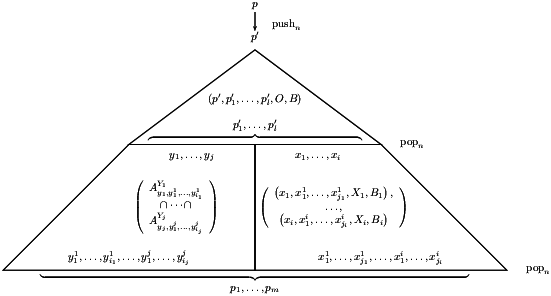
We explain the rules of P−1 intuitively. It will be beneficial to refer to the formal definition (below) while reading the explanations. The case for Rpush is illustrated in Figure 5 since it covers most of the situations appearing in the other rules as well.
Similarly, in the current subtree we are obliged to pop to leaf nodes containing the control states p1, …, pm. We split these obligations between the branches we are exploring and those we are handling using tests. We use another permutation check to ensure the obligations have been distributed properly.
Finally, we are required to output characters in O. We may also, in choosing a particular branch for a character a, need to output a to account for instances appearing on a missed branch. Hence we also output O′ to account for these. We distribute the obligations O and O′ amongst the different branches using X1, …, Xi and Y1, …, Yj.
In these rules, after the push we’re in control state p′ and we guess that we will pop to control states p′1, …, p′l. Hence we have a branch or a test to ensure that this happens. The remaining branches and tests are for what happens after the pops. The start from the states p′1, …, p′l and must, in total, pop to the original pop obligation p1, …, pm. Hence, we distribute these tasks in the same way as the Rbr.
Before giving the formal definition, we summarise the discussion above by recalling the meaning of the various components. A control state (p, p1, …, pm, O, B) means we’re currently simulating a node at control state p that is required to produce m branches terminating in control states p1, …, pm respectively, that the produced tree should output at least one of each character in O and the entire subtree should output enough of each character in B to satisfy the diagonal problem. In the definition below, the set O′ is the set of new single character output obligations produced when the automaton decides which branches to follow faithfully and which to test (for the output of at least one of each character). The sets X1, …, Xi and Y1, …, Yj represent the partitioning of the single character output obligations amongst the tests and new branches.
The correctness of the reduction is stated after the definition. A discussion of the proof appears in Section 7.
| P−1 = | ⎛ ⎝ | P−1, Σ, Γ, R−1, F−1, pin−1, γin, θ−1 | ⎞ ⎠ |
|
|
| ⎛ ⎝ | pin−1, γin | ⎞ ⎠ | —ε→ | ⎛ ⎜ ⎝ |
| ⎞ ⎟ ⎠ |
| ⎛ ⎝ |
| ⎞ ⎠ | —ε→ | ⎛ ⎝ | f, rewγ | ⎞ ⎠ |
| ⎛ ⎝ |
| ⎞ ⎠ | — |
| → | ⎛ ⎜ ⎝ |
| ⎞ ⎟ ⎠ |
| ⎛ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎠ | —O′ ⋂ B→ | ⎛ ⎜ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎟ ⎠ |
| ⎛ ⎝ | p, γ | ⎞ ⎠ | —ε→ | ⎛ ⎝ | p′1, …, p′l, rewγ | ⎞ ⎠ | ∈ R |
| x1, …, xi, y1, …, yj |
| x11, …, xj11, … x1i, …, xjii y11, …, yi11, … y1j, …, yijj |
| O ⋃ O′ = X1 ⋃ ⋯ ⋃ Xi⋃ Y1 ⋃ ⋯ ⋃ Yj |
| ⎛ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎠ | —O′ ⋂ B→ | ⎛ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎠ |
| ⎛ ⎝ | p, γ | ⎞ ⎠ | —ε→ | ⎛ ⎝ | p′, pushn | ⎞ ⎠ |
| x1, …, xi, y1, …, yj |
| x11, …, xj11, … x1i, …, xjii y11, …, yi11, … y1j, …, yijj |
| O ⋃ O′ = X ⋃ X1 ⋃ ⋯ ⋃ Xi⋃ Y1 ⋃ ⋯ ⋃ Yj |
| ⎛ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎠ | —O′ ⋂ B→ | ⎛ ⎜ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎟ ⎠ |
| ⎛ ⎝ | p, γ | ⎞ ⎠ | —ε→ | ⎛ ⎝ | p′, pushn | ⎞ ⎠ |
| x1, …, xi, y1, …, yj |
| x11, …, xj11, … x1i, …, xjii y11, …, yi11, … y1j, …, yijj |
| O ⋃ O′ = Y ⋃ X1 ⋃ ⋯ ⋃ Xi⋃ Y1 ⋃ ⋯ ⋃ Yj |
In Section 7 we show that the reduction is correct.
To complete the reduction, we convert the (n, α)-PDA with tests into a (n, α)-PDA without tests.
| Diagonala1, …, aα | ⎛ ⎝ | P | ⎞ ⎠ | ⇐⇒ Diagonala1, …, aα | ⎛ ⎝ | P′ | ⎞ ⎠ | . |
Proof. From Definition 4 (P−1) and Lemma 2 (Correctness of P−1), we obtain from P an (n−1, α)-PDA with tests P−1 satisfying the conditions of the lemma. To complete the proof, we invoke Theorem 1 (Removing Tests) to find P′ as required.
We show correctness of the reduction in Section 7. First we show that we have decidability once we have reduced to order-0.
We show that the problem becomes decidable for a 0-PDA P. This is essentially a finite state machine and we can linearise the trees generated by saving the list of states that have been branched to in the control state. After one branch has completed, we run the next in the list, until all branches have completed. Hence, a tree of P becomes a run of the linearised 0-PDA, and vice-versa. Since each output tree has a bounded number of branches, the list length is bounded. Thus, we convert P into a finite state word automaton, for which the diagonal problem is decidable. Note, this result can also be obtained from the decidability of the diagonal problem for pushdown automata.
| = | ⎛ ⎜ ⎝ |
| ⎞ ⎟ ⎠ |
| P = | ⎧ ⎪ ⎨ ⎪ ⎩ |
| ⎪ ⎪ ⎪ ⎪ |
| ⎫ ⎪ ⎬ ⎪ ⎭ | ⋃ | ⎧ ⎨ ⎩ | f | ⎫ ⎬ ⎭ |
| ⎛ ⎝ |
| ⎞ ⎠ | —b→ | ⎛ ⎜ ⎝ |
| ⎞ ⎟ ⎠ |
| ⎛ ⎝ | p, γ | ⎞ ⎠ | —b→ | ⎛ ⎝ | p′1, …, p′l, rewσ | ⎞ ⎠ | ∈ R |
| ⎛ ⎝ |
| ⎞ ⎠ | —ε→ | ⎛ ⎝ |
| ⎞ ⎠ |
| Diagonala1, …, aα | ⎛ ⎝ | P | ⎞ ⎠ | ⇐⇒ Diagonala1, …, aα | ⎛ ⎜ ⎝ |
| ⎞ ⎟ ⎠ |
Proof. Take an accepting run tree ρ of P. If this tree contains no branching, then it is straightforward to construct an accepting run of P. Hence, assume all trees with fewer than α branches have a corresponding run of P. At a subtree c[T1, …, Tm] we take the run trees ρ1, …, ρm corresponding to the subtrees. Let c = ⟨ p, γ ⟩ and c1 = ⟨ p1, γ ⟩, …, cm= ⟨ pm, γ ⟩ be the configurations at the roots of the subtrees. We build a run beginning at c and transitioning to ⟨ (p1, p2, γ, …, pm, γ), γ ⟩. The run then follows ρ1 with the extra information in its control state. After ρ1 accepts, we transition to ⟨ (p2, p3, γ, …, pm, γ), γ ⟩ and then replay ρ2. We repeat until all subtrees have been dispatched. This gives an accepting run of P outputting the same number of each a.
In the other direction, we replay the accepting run ρ of P until we reach a configuration ⟨ (p1, p2, γ, …, pm, γ), γ ⟩ via a rule
| ⎛ ⎝ | p, σ | ⎞ ⎠ | —ε→ | ⎛ ⎝ |
| ⎞ ⎠ |
At this point we apply
| ⎛ ⎝ | p, σ | ⎞ ⎠ | —ε→ | ⎛ ⎝ | p1, …, pm, rewγ | ⎞ ⎠ |
of P. We obtain runs for each of the new children as follows. We split the remainder of the run ρ′ into m parts ρ′1, …, ρ′m where the break points correspond to each application of a rule of the second kind. For each i we replay the transitions of ρ′1 from ⟨ pi, γ ⟩ to obtain a new run of P with fewer applications of the second rule. Inductively, we obtain an accepting run of P that we plug into the ith child. This gives us an accepting run of P outputting the same number of each a.
We thus have the following theorem.
Proof. We first interpret P as an (n, α)-PDA and then construct via Lemma 3 (Reduction to Lower Orders) an (n−1, α)-PDA P′ such that Diagonala1, …, aα(P) iff Diagonala1, …, aα(P′). We repeat this step until we have an (0, α)-PDA. Then, from Lemma 4 (Decidability at Order-0) we obtain decidability as required.
In this section we prove Lemma 2 (Correctness of P−1). The proof follows the same outline as the single character case. To show there is a run with at least m of each character, we take via Lemma 1 (Section 7.2), m′ = (α+1)m, and a run of P outputting at least this many of each character. Then from Lemma 2 (Section 7.3) a run of P−1 outputting at least m of each character as required. The other direction is shown in Lemma 3 (Section 7.4).
We first generalise our tree decomposition and notion of scores. We then show that every α-branch subtree of a tree decomposition generates a run tree of P−1 matching the scores of the tree. Finally we prove the opposite direction.
Given an output tree T of P where each pushn operation has a matching popn on all branches, we can construct a decomposed tree representation of the run inductively as follows. We define Tree(T[ε]) = T[ε] and, when
| T = b | ⎡ ⎣ | T1, …, Tm | ⎤ ⎦ |
where the rule applied at the root does not contain a pushn operation, we have
| Tree | ⎛ ⎝ | T | ⎞ ⎠ | = b | ⎡ ⎣ |
| ⎤ ⎦ | . |
In the final case, let
| T = ε | ⎡ ⎣ | T′ | ⎤ ⎦ |
where the rule applied at the root contains a pushn operation and the corresponding popn operations occur at nodes η1, …, ηm.
Note, if the output trees had an arbitrary number of branches, m may be unbounded. In our case, m ≤ α, without which our reduction would fail: P−1 would be unable to accurately count the number of popn nodes. In fact, our trees would have unbounded out degree and Lemma 1 (Minimum Scores) would not generalise.
Let T1, …, Tm be the output trees rooted at η1, …, ηm respectively and let T′ be T with these subtrees removed. Observe all branches of T are cut by this operation since the pushn must be matched on all branches. We define
| Tree | ⎛ ⎝ | T | ⎞ ⎠ | = ε | ⎡ ⎣ |
| ⎤ ⎦ | . |
An accepting run of P has an extra popn operation at the end of each branch leading to the empty stack. Let T′ be the tree obtained by removing the final popn-induced edge leading to the leaves of each branch. The tree decomposition of an accepting run is
| Tree | ⎛ ⎝ | T | ⎞ ⎠ | = ε | ⎡ ⎣ |
| ⎤ ⎦ |
where there are as many T[ε] as there are leaves of T.
Notice that our trees have out-degree at most (α + 1).
We score branches in the same way as the single character case. We simply define Scorea(ρ) to be Score(ρ) when a is considered as the only output character (all others are replaced with ε).
We have to slightly modify our minimum score lemma to accommodate the increased out-degree of the nodes in the trees.
| Scorea | ⎛ ⎝ | T | ⎞ ⎠ | ≥ log(α+1) | ⎛ ⎝ | m | ⎞ ⎠ |
Proof. This is a simple extension of the proof of Lemma 1 (Minimum Scores). We simply replace the two-child case with a tree with up to (α+1) children. In this case, we have to use log(α+1) rather than log to maintain the lemma.
Proof. We will construct a tree ρ−1 in L(P−1) top down. At each step we will maintain a “frontier” of ρ−1 and extend one leaf of this frontier until the whole tree is constructed. The frontier is of the form
| ⎛ ⎝ | c1, η1, O1, B1, …, cl, ηl, OlBl | ⎞ ⎠ |
which means that there are l nodes in the frontier. We have B1 ⊎ ⋯ ⊎ Bl= {a1, …, aα} and each Bi indicates that the ith branch, ending in configuration ci, is responsible for outputting enough of each of the characters in Bi. Each ηi is the corresponding node in Tree(ρ) that is being tracked by the ith branch of the output of P−1.
Let pf be the final (accepting) control state of P and let T = Tree(ρ). We begin at the root node of T, which corresponds to the initial configuration of ρ. Let ⟨ p, [s]n ⟩ be this initial configuration and let c = ⟨ (p, pf, …, pf, ∅, {a1, …, aα}), s ⟩ be the configuration of P−1 after an application of a rule from Rinit. The initial frontier is (c, ε, {a1, …, aα}).
Thus, assume we have a frontier
| ⎛ ⎝ | c1, η1, O1, B1, …, ch, ηh, Oh, Bh | ⎞ ⎠ |
and for each of the sequences c−1, η, O, B of the frontier we have
Pick such a sequence c−1, η, O, B. We replace this sequence using a transition of P−1 in a way that produces a new frontier with the above properties and moves us a step closer to reaching leaves of T. There are three cases when we are dealing with internal nodes.
In this case there is a transition c —b→ c′ via a rule (p, γ) —b→ (p′, o) where o ∉ {pushn, popn}. Hence, we have
| ⎛ ⎝ |
| ⎞ ⎠ | — |
| → | ⎛ ⎜ ⎝ |
| ⎞ ⎟ ⎠ |
in P−1 and thus we can extend ρ−1 with a transition c−1 —b→ c′−1 via this rule. The new frontier is obtained by replacing c−1, η, O, B with c′−1, η′, O ∖ {b}, B where η′ is the child of η. The properties on the frontier are easily seen to be retained.
We separate B = B′1 ⊎ ⋯ ⊎ B′i such that B′j is the set of characters a that have their score derived from Tj (i.e. the subtree with the higher score for a characters). Let O′ be the set of all a who had a +1 in their score derived from another subtree. Let ⟨ x1, s ⟩, … ⟨ xi, s ⟩ be the configurations labelling the root nodes η0, η1, …, ηi of these subtrees. Let ⟨ y1, s ⟩, …, ⟨ yj, s ⟩ be the configurations labelling the root nodes of the remaining subtrees. Since T′ includes m leaves that are followed in ρ by pops to p1, …, pm we can distribute these control states amongst the branches, obtaining
| x11, …, xj11, … x1i, …, xjii y11, …, yi11, … y1j, …, yijj . |
Finally, we can distribute
| O ⋃ O′ = X1 ⋃ ⋯ ⋃ Xi⋃ Y1 ⋃ ⋯ ⋃ Yj |
amongst the subtrees T1, …, Tl since O can be distributed by assumption and we chose O′ such that this can be done.
From the runs corresponding to T1, …, Tl and our choices above we know that the tests will pass. That is, c−1 ∈ L(Ap′1,y11,…,yi11Y1), …, c−1 ∈ L(Ap′j,y1j,…,yijjYj).
Hence, we apply to c−1 the rule
| ⎛ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎠ | —O′ ⋂ B→ | ⎛ ⎜ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎟ ⎠ |
and obtain configurations c−11, …, c−1i and a new frontier satisfying the required properties by replacing c−1, η, O, B with the sequence
| c−11, η1, X1, B′1, … c−1i, ηi, Xi, B′i . |
In this case we have that T′ (subtree of the decomposition T) corresponds to a run tree ρT′ that can be decomposed into
There are two cases depending on whether we send the HOPDA down the branch corresponding to the push.
| x11, …, xj11, … x1i, …, xjii y11, …, yi11, … y1j, …, yijj . |
| O ⋃ O′ = X ⋃ X1 ⋃ ⋯ ⋃ Xi⋃ Y1 ⋃ ⋯ ⋃ Yj |
From the existence of the runs ρ1, …, ρl we know c−1 ∈ L(Ap′1,y11,…,yi11Y1), …, c−1 ∈ L(Ap′j,y1j,…,yijjYj).
Hence, we apply to c−1 the rule
| ⎛ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎠ | —O′ ⋂ B→ | ⎛ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎠ |
and obtain configurations c−10, c−11, …, c−1i and a new frontier satisfying the required properties by replacing c−1, η, O, B with the sequence
| c−10, η0, X, B′0, c−11, η1, X1, B′1, … c−1i, ηi, Xi, B′i . |
| x11, …, xj11, … x1i, …, xjii y11, …, yi11, … y1j, …, yijj . |
| O ⋃ O′ = X1 ⋃ ⋯ ⋃ Xi⋃ Y ⋃ Y1 ⋃ ⋯ ⋃ Yj |
From the existence of ρ′ we know that c−1 ∈ L(Ap′,p′1,…,p′lY) and from the existence of ρ1, …, ρl we also know c−1 ∈ L(Ap′1,y11,…,yi11Y1), …, c−1 ∈ L(Ap′j,y1j,…,yijjYj).
Hence, we apply to c−1 the rule
| ⎛ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎠ | —O′ ⋂ B→ | ⎛ ⎜ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎟ ⎠ |
and obtain configurations c−11, …, c−1i and a new frontier satisfying the required properties by replacing c−1, η, O, B with the sequence
| c−11, η1, X1, B′1, … c−1i, ηi, Xi, B′i . |
Finally, we reach a leaf node η with a run outputting the required number of as. We need to show that the run constructed is accepting. From the tree decomposition, we know that the corresponding node of ρ is immediately followed by a popn. Thus, from our conditions on the frontier, we must have m = 1 and O = ∅. We also have a rule (p, γ) —ε→ (p1, popn) and therefore ((p, p1, ∅, B), γ, Att) —ε→ (f, rewγ) with which we can complete the run of P−1 as required.
Finally, we need to show that each accepting run tree of P−1 gives rise to an accepting run tree of P containing at least as many of each output character a.
Proof. Take an accepting run tree ρ−1 of P−1. We show that there exists a corresponding run tree ρ of P outputting at least as many as.
We maintain a frontier
| c1, …, ch |
of ρ−1 and a run ρ of P “with holes” such that
Initially after a rule from Rinit we have the frontier c = ⟨ (p, pf, …, pf, ∅, {a1, …, aα}), s ⟩ with corresponding run ρ of P being
| ⎡ ⎣ |
| ⎤ ⎦ | . |
Pick a configuration c−1 = ⟨ (p, p1, …, pm, O, B), topn(s) ⟩ of the frontier that is not a leaf of ρ−1 and its corresponding node in ρ with parent labelled c = ⟨ p, s ⟩. Let ρ′−1 be the subtree of P−1 rooted at this configuration.
We show how to extend the frontier closer to the leaves of ρ−1. There are several cases depending on the transition of P−1 used to exit our chosen node.
| ⎛ ⎝ |
| ⎞ ⎠ | — |
| → | ⎛ ⎜ ⎝ |
| ⎞ ⎟ ⎠ | . |
| ⎛ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎠ | —O′ ⋂ B→ | ⎛ ⎜ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎟ ⎠ |
| ⎛ ⎝ | p, γ | ⎞ ⎠ | —ε→ | ⎛ ⎝ | p′1, …, p′l, rewγ | ⎞ ⎠ | ∈ R . |
The new frontier replaces c−1 with
|
which satisfies all properties as needed.
| ⎛ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎠ | —O′ ⋂ B→ | ⎛ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎠ |
| ⎛ ⎝ | p, γ | ⎞ ⎠ | —ε→ | ⎛ ⎝ | p′, pushn | ⎞ ⎠ |
| ⟨ |
| , |
| ⟩ . |
These nodes have configurations ⟨ p′1, s ⟩, …, ⟨ p′l, s ⟩ (since s = popn(pushn(s))). These control states are distributed between x1, …, xi and y1, …, yj. Consider y1 (the other y2, …, yj are identical). We have from the passed test that ⟨ y1, s ⟩ has a run where the first popping of the topn stack leads to configurations ⟨ y11, popn(s) ⟩, …, ⟨ yi11, popn(s) ⟩. We append this run tree as a child of the node corresponding to y1. Since y11, …, yi11 appear amongst p1, …, pm we append the relevant subtrees we had already constructed for these nodes to complete these branches with the required properties.
Now consider x1 (the other cases are symmetric). In this case we append a node labelled ⟨ (x1, x11, …, xj11, X1, B1), topn(s) ⟩ as a child of the node corresponding to x1. Since x11, …, xj11 appear amongst p1, …, pm we append the relevant subtrees we had already constructed for these nodes to complete these branches with the required properties.
The new frontier replaces c−1 with
| ⟨ |
| , |
| ⟩ |
and
|
which satisfies all the required properties.
| ⎛ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎠ | —O′ ⋂ B→ | ⎛ ⎜ ⎜ ⎜ ⎜ ⎝ |
| ⎞ ⎟ ⎟ ⎟ ⎟ ⎠ |
| ⎛ ⎝ | p, γ | ⎞ ⎠ | —ε→ | ⎛ ⎝ | p′, pushn | ⎞ ⎠ |
These leaf nodes are completed using the same argument as the previous case. That is, they are labelled with configurations ⟨ p′1, s ⟩, …, ⟨ p′l, s ⟩. These control states are distributed between x1, …, xi and y1, …, yj. Consider y1 (the other y2, …, yj are identical). We have from the passed test that ⟨ y1, s ⟩ has a run where the first popping of the topn stack leads to configurations ⟨ y11, popn(s) ⟩, …, ⟨ yi11, popn(s) ⟩. We append this run tree as a child of the node corresponding to y1. Since y11, …, yi11 appear amongst p1, …, pm we append the relevant subtrees we had already constructed for these nodes to complete these branches with the required properties.
Now consider x1 (the other cases are symmetric). In this case we append a node labelled ⟨ (x1, x11, …, xj11, X1, B1), topn(s) ⟩ as a child of the node corresponding to x1. Since x11, …, xj11 appear amongst p1, …, pm we append the relevant subtrees we had already constructed for these nodes to complete these branches with the required properties.
The new frontier replaces c−1 with
| ⟨ |
| , |
| ⟩ |
and
|
which satisfies all the required properties.
In this case c has the form
| ⟨ |
| , |
| ⟩ |
and there is a rule
| ⎛ ⎝ | p, γ | ⎞ ⎠ | —ε→ | ⎛ ⎝ | p′, popn | ⎞ ⎠ | . |
We can remove the hole from ρ by applying this rule. That is, we remove the hole node, setting its parent to have its (only) child as its child. This is possible since by our conditions the child has the label ⟨ p′, popn(s) ⟩. We remove c−1 from the frontier.
Thus, the frontier moves towards the leaves of the tree and finally is empty. At this point we have an accepting run of P as required. To see that the run outputs enough of each character, one needs to observe that at each stage the tests and O component of the control state ensured at least one character output for each that appeared in some O′ labelling a transition. Then, for characters output along branches followed were reproduced faithfully.
We have shown, using a recent result by Zetzsche, that the downward closures of languages defined by HOPDA are computable. We believe this to be a useful foundational result upon which new analyses may be based. Our result already has several immediate consequences, including separation by piecewise testability and asynchronous parameterised systems.
Regarding the complexity of the approach. We are unaware of any complexity bounds implied by Zetzsche’s techniques. Due to the complexity of the reachability problem for HOPDA, the test automata may be a tower of exponentials of height n for HOPDA of order n. These test automata are built into the system before proceeding to reduce to order (n−1). Thus, we may reach a tower of exponentials of height O(n2).
A natural next step is to consider collapsible pushdown systems, which are equivalent to recursion schemes (without the safety constraint). However, it is not currently clear how to generalise our techniques due to the non-local behaviour introduced by collapse. We may also try to adapt our techniques to a higher-order version of BS-automata [3], which may be used, e.g., to check boundedness of resource usage for higher-order programs.
We thank Georg Zetzsche for keeping us up to date with his work, Jason Crampton for knowing about logarithms when they were most required, and Chris Broadbent for discussions. This work was supported by the Engineering and Physical Sciences Research Council [EP/K009907/1 and EP/M023974/1].
This document was translated from LATEX by HEVEA.